Tyger 1: Prelude and Lexing
So I decided to make a programming language; how hard could it be?
This post is part of a series, click here to read more.
Tyger is a dynamically typed, interpreted, scripting language, developed as an extension of, and inspired by Thorsten Ball’s book, Writing An Interpreter In Go. I wanted a more complex project to get my teeth into that would improve my both my skills as a programmer generally, and with C programming (specifically). The aforementioned book is a fantastic resource, and I would recommend people check it out, even if language development isn’t something you’re super interested in as it’s just a good resource to work through (try translating it into your language of choice for a challenge!)
As mentioned, I wanted to improve my C skills and my general programming ability. To me, it seems C provides the best opportunity for this as
- it is low level (defined as giving you fine control over memory)
- it features no garbage collection
- garbage collection is a feature I have used, as I have used several languages which implement it (including Go, Python, and JavaScript)
- I would like to try implementing it, to get a better appreciation of how it works
- many convieniences present in Go are non-existent in C:
- count-based strings, and arrays
- UTF-8 support (well it is there as part of the standard library, but I don’t like working with null terminated strings)
- automatic serialization of types (kind of, the most useful example is being able
to stringify a struct implicitly with
%v/%+vformat specifiers)
The interpreter is written specifically using the C99 standard; I chose this, primarily, for the following reasons:
- “C++” style comments, until C99 all comments had to be defined between
/**/ stdint.hwhich provides a nice series of fixed witdth int definitions- no more checking whether an int is
2or4bytes (nice when required)!
- no more checking whether an int is
- designated initialisers for structs and unions
- no forced forward declaration of variables
- in C89 you needed to declare all variables used in a scope at the beginning of the scope
- C99 relaxes this and allows you to declare only when required
The Basic Outline
What I am going to implement, at least initially, is an interpreter capable of running the following program:
var x = 10;
var y = x + 5 - 4 * 3 / 2;
println(x, y);
println("Hello, World!");
To do this, I need to implement a lexer capable of lexing
- identifiers
- e.g.
x, andy - builtin functions (i.e.
println)
- e.g.
- keywords
- i.e.
var
- i.e.
- string and integer literals
- binary infix operators
I will also need to parse these lexed tokens into an Abstract Syntax Tree (AST), the program will be interpreted using a tree-walk interpreter, finally, I will need to implement a garbage collector (although until more complex constructs are implemented this may be hard to properly validate the function of).
I will not be implementing ability to handle comments, functions, or control flow
yet (loops, if/else, etc); I also will not implement things such as block statements
(a series of statements bounded by { ... }), return statements, constant vs variable
binding, macros, classes, packages/modules, or a C FFI (foreign function interface).
This is a brief list, and not exhaustive.
All of these are things I would like to implement, however I am trying to keep the scope quite radically small to ensure I can, and will finish it. Even so, the breadth of what needs doing is quite large, mainly due to several technical challenges that will come out of this, such as:
- memory management, I’m discussing the management of the interpreter memory here,
not the process of garbage collection
- i.e. allocating the AST, where to store variables and idents until evaluation, etc
- error handling (“traditionally” C programs will use int return codes, or set
errno, I would like to trial something different) - how to actually handle the process of constructing an AST
- type resolution
- i.e. whem a variable encountered, derive the type so evaluating operations can be handled appropriately
Perparing The Ground
Build Systems
I decided to go with CMake for this project, not out of a real like for it it, mainly because
- it’s fine
- I’ve used it before
- it has easy setup to allow me to get started with GTest
Normally, CMake is not my main choice, I tend to just dump things in batch/shell scripts, and use those to build my projects. I may add these later, mainly for end user convienience if they should choose to compile it themselves. As a result of my… ambivalance… towards CMake, I choose to keep the scripts as minimal as possible, and as a result the extent of the build system is:
- set C99 and C++14 as the target standard used in compilation
- C99 is for the “library” build and the main interpreter exe
- C++14 is required for GTest
- compile a “library” binary, containing all files which require testing
- compile the interpreter, linking it against the “library” generated
- setup, and compile the test runner executable
I also make sure I set a handful of compiler flags:
if (MSVC)
add_compile_options(/W4 /w14640 /WX /permissive- /Zi /Od)
else()
add_compile_options(-Wall -Wextra -Werror -Wshadow -pedantic -g -O0)
endif()
This is hardly extensive, and probably requires some tweaking, but for now it’s good enough. In essence, the aim is to have
- the maximum number of warnings enabled possible
- treat all warnings as errors
- enable debug info
- disable optimisations (no real reason for this, besides making inspection of any generated code easier)
You can inspect the full build file if you wish, but further delving into the build system hardly seems interesting, or germane to the topic at hand.
Test Driven Development
I think Test Driven Development (TDD) has a time and a place; namely, where you are dealing with well defined input and output requirements. For example, assume you were to design a library containing some basic maths and linear algebra functions, this would be a good case for TDD as, for example, you can define that
- function
vector2_scaleshould scale the magnitude of the vector appropriately - some example inputs/outputs:
vector2_scale(Vector2{ 1, 1 }, 5) == Vector2{ 5, 5 }vector2_scale(Vector2{ 10, 10 }, 0.2) == Vector2{ 2, 2 }vector2_scale(Vector2{ 1, 1 }, -1) == Vector2{ -1, -1 }
Since I can quite easily define the expected inputs, and outputs for each stage of program interpretation, I have decided to employ this as a test strategy in the development of my interpreter, at least initially.
Now to actually perform the testing, I will be using the C++ testing library GTest to run tests, mainly because it’s one I had seen recommended and it’s also one I have some experience with from other (dead) side projects I’ve worked on. GTest has some interesting features, one of which I only found documented in a Stack Overflow thread, this being the ability to supply extra diagnostic messages when assertions/expectations fail via streams:
...
int res = 2 + 2;
ASSERT_EQ(res, 5)
<< "... Sometimes they are five. Sometimes they are three. Sometimes they are all of them at once..."
...
This is particularly useful when coupled with running comparisons on enums, since, when these are output to console, they are (implicitly) converted to integers (at least in C), and it’s hard to translate that to what you’ve written.
Generating Test Case Code
Part of what I want to do in this project is include good error diagnostic messages for users, as a result, even though it won’t be implemented fully, I am scaffolding out a lot of this early. As a result, this will require me to write a lot of finicky tests involving counting column and line numbers to verify reporting is correct. This is tedious, and potentially error prone, I have decided that a certain degree of duplication of work is acceptable. In this case, I am duplicating the code that will be used to create the Lexer, to automatically generate:
- Test cases (the expected tokens)
- The suite of Enumerants of what kind of tokens are supported
- A dump of the source code used to generate the tests
Since the code is mostly a duplicate of that implemented in the actual lexer, I will omit explanations of the code, and defer you to my next section; however, for those keen to purose - or those more confident with Python than C - I will link the script here.
One thing I will touch on as an interesting issue, which caused some confusion initially, was line endings; oh yes, they’re still causing problems in <current year>!
The main issue that I found, was because I chose to load a separate file from disk
(rather than just handling the string as a raw literal within the script) I immediately
encountered issues in my CI workflow to do with different offsets of all tokens
within the test cases compared to what was actually generated. This is because \r\n
(what was present on the Windows machine I used) were assumed to be present in the file,
and the CI ran using Linux, which uses \n line endings (legacy versions of MacOS
used \r but this is less common now).
This is simple to solve, but I will tackle this problem later; the solution, I think, is to only do tests for the location of the token in the file as a measure of line and column position (and omit checking the absolute position in the file).
Now enough preamble. The code proper!
Lexical Analysis
The first step in parsing a language is to convert the text into a stream of tokens.
This is done as it is easier to work assign meaning when parsing when you operate
on a higher level than individual characters; for example, operating on a token of
type Var_Keyword is easier than deciding what needs to be done with the char v
as this could be a keyword, an identifier, or a keyword wrongly being used in place
of an identifer (e.g. as an identifier).
Defining The Process
I am essentially copying the model defined in the book,
but before we get to that, I want to outline the end usage code, and then define
what we need to happen within the code. Every time we want to get the next token,
we need to call lexer_next_token(&lexer), passing in a pointer to a Lexer struct.
This function then needs to perform the following:
- skip whitespace, since in this language it is not significant (unlike Python)
- match the current character the lexer is “looking at”
- decide, based on the current char, how to transform this into a token
- advance the lexer
- return the generated token
Defining The Lexer
As mentioned, this comes from the book, but is modified to (a) add debug information
in the form of column and line numbers (although this is unsused for now), and (b)
track the length of the input string. The later of these is required since Go
tracks this information implicitly by means of the string type; in C strings
are null terminated (by default), for now I will be deriving the length of the string
once during initialisation, rather than running strlen each time a call to lexer_read_char
or lexer_peek_char is made.
typedef struct lexer
{
const char *program; // The input string to lex
size_t program_len; // The length of the input string (in bytes)
size_t pos; // The current offset from the start of the string (in bytes)
size_t read_pos; // The next offset from which the lexer will read the char (in bytes)
size_t col; // The current column in the file the lexer is reading (unused)
size_t line; // The current line in the file the lexer is reading (unused)
char ch; // The current character the lexer is reading
} Lexer;
Initialisation of the lexer looks like this:
void lexer_init(Lexer *lx, const char *program)
{
lx->program = program;
lx->pos = 0;
lx->read_pos = 0;
lx->col = 0;
lx->line = 0;
lx->ch = '\0';
size_t prog_len = strlen(program);
lx->program_len = prog_len;
lexer_read_char(lx);
}
There is an annoyance I have here, nameley that we are reliant on strlen and the
fact our input will be properly null terminated. Fow this is okay, but when hooking
this code into the actual program (and not just passing char* to the function)
I will need to take special care to ensure the input string is properly formatted
(whether this be from REPL input, or from reading a file).
Tokenisation
Onto the process of generating Tokens from source code…
Token lexer_next_token(Lexer *lx)
{
// 1. skip whitespace
lexer_skip_whitespace(lx);
// 1.5. default construct the Token
Token token = {
.location = make_location(lx->pos, lx->col, lx->line),
.literal = make_string_view_ex(lx->program, lx->pos, 1),
};
// 2. Match the current character being inspected by the lexer
switch (lx->ch)
{
// 3. based on what character is matched, generate the appropriate token
...
}
// advance the lexer to read the next char
lexer_read_char(lx);
return token;
}
Default token construction contains 2 macro calls, these are present to make the
process of creating the nested strcuts a little more pleasant, particularly as
the make_string_view_ex macro performs some pointer tricks to generate a pointer
which is offset from the initial pointer, which is quite noisy. Expansion of the
macro yields (String_View) { &(lx->program[lx->pos]), 1 }.
The reasons for setting the default state of the Token are:
- all tokens, after skipping whitespace, will be found at the location the lexer currently points at (i.e. the absolute offset, col, and line number)
- many tokens will be of small length (1), so it makes sense to just pre-populate
that and worry about updates to it later
- The tokens which are of length 1 include:
( ) { } [ ] + - * / = ! < >
- The tokens which are of length 1 include:
Perhaps, as more tokens are added, I will change my mind on setting the default representation of the literal to not be of length 1, but for now I think it’s worth setting the default.
Defining Our Tokens
Now we’ve seen the way the lexer is defined, and how new tokens are generate, it makes sense to dive in to how these tokens are structured:
typedef struct token
{
Location location; // A representation of where in the source code the token was found
String_View literal; // A representation of the underlying string the token represents
Token_Kind kind; // A tag representing the kind of token this is
} Token;
Where Location is defined as
typedef struct location
{
size_t pos;
size_t col;
size_t line;
} Location;
and String_View as
typedef struct stirng_view
{
char *str;
size_t len;
} String_View;
We will touch on how the Token_Kind is defined later,
for now it is sufficient to say it is an enum.
String_Views
A Note About Memory Allocation
Dynamic memory allocation is one of those things before I got started with C programming I never really understood; neither the actual process, nor the reasons why you would want/need to use this method. It is important to note that for a while the only languages I ever really used for the first 4-5 years or me programming were Python, Java, and JavaScript, all garbage collected languages.
At some stage I got annoyed at not understanding this whole process and wanted to dive deeper (even if I thought I’d never use it), so I started writing a CLI program which would take a DNA/RNA string as its input and convert it the corresponding RNA/DNA sequence. The code for this has been lost, but it did begin the journey of understanding memory management at a lower level than that afforded by garbage collection.
The first thing I did, is what I beleive most, if not all, budding C developers
do when they first reach for dynamic memory allocation strategies, which to to
emulate RAII. What I mean by this, is every <object>_alloc(...) call is followed
by a corresponding <object>_free(...) call. Whilst this is fine, there are still
some problems with this style of allocation:
- it is important to note that every allocation takes time, as does each free.
- every allocation can fail, now on modern operating systems and hardware this may indicate a much more serious problem, but it is still an extra point of failure that you need to check, such as you don’t write/access some null pointer.
- this is less robust than RAII, mainly because you the programmer are now responsible for correctly handling the ending of each object lifetime at every scope/function exit. That means all happy and unhappy paths!
- (what I consider most) importantly it is incredibly difficult to track object
lifetimes, not only within a function call, but across function calls, and decide
who is responsible for handling cleanup.
- this bleeds a little out from the prior point on RAII.
The last point is particularly true once the number of objects (of potentially differing lifetimes and types) increases beyond a [small] handful! Ownership is also increasingly problematic to keep track of. This situation is what I have seen be referred to as the lifetime soup.
A much better approach, if possible, is to group lifetimes together and handle the deallocation of backing resources in batches. Take for example, a program which reads some input file and splits the text into its constituent words by whitespace, let us for now assume that the programmer wishes to echo these words to stdout, and possibly retain a count of the number of words found.
One solution could look something like this, where each word is allocated as a small string, then freed after printing:
int main(int argc, const char *argv[])
{
// function is assumed to exist
const char *file = read_entire_file_into_memory(argv[1]);
size_t index = 0;
int word_count = 0;
while (file[index] != '\0')
{
size_t buffer_start = index;
size_t buffer_offset = index;
// NOTE: this a function assumed to exist which checks for " ", \n, \r, \t
while (!is_whitespace(file[buffer_offset++])) {}
size_t bytes_read = buffer_offset - buffer_start;
// remember space for null terminator
char *word = malloc(sizeof(char) * (bytes_read + 1));
strncpy(word, &(file[index]), bytes_read);
word[bytes_read] = '\0';
printf("%s\n", word);
free(word);
word_count += 1;
index += bytes_read;
}
free(file);
}
Every time through this loop, we allocate a string, then print, then free. Now whilst the allocation, usage, and deallocation of the resource (our string) are colocated, so the lifetime of the object (the string) is obvious, this is very often not the case in reality (the colocation of allocation, usage, and deallocation). We may, in this case and more generally, be better served by a different strategy.
int main(int argc, const char *argv[])
{
// allocate a backing buffer capable of storing 256 chars
size_t word_buffer_len = 0;
size_t word_buffer_capacity = 256;
char *word_buffer = malloc(sizeof(char) + word_buffer_capacity);
// function is assumed to exist
const char *file = read_entire_file_into_memory(argv[1]);
size_t index = 0;
int word_count = 0;
while (file[index] != '\0')
{
size_t word_start = index;
size_t word_next = index;
while (!is_whitespace(file[word_next++])) {}
size_t word_len = word_next - word_start;
if (word_buffer_len + word_len >= word_buffer_capacity)
{
size_t new_capacity = word_buffer_capactiy * 2;
word_buffer = realloc(word_buffer, sizeof(char) * new_capacity);
word_buffer_capacity = new_capacity;
}
strncpy(&(word_buffer[word_buffer_len]), &(file[index]), word_len);
word_buffer[word_buffer_len + word_len] = '\0';
word_buffer_len += (word_len + 1);
word_count += 1;
index += word_len;
}
char *next_word = word_buffer;
for (size_t i = 0; i < word_count; ++i)
{
printf("%s\n", next_word);
while (*next_word++ != '\0') {}
}
free(word_buffer);
free(file);
}
The later of these 2 requires some more code to be present, however we are not in a state where every word registerd requires us to allocate a new buffer, then delete. Instead we allocate one backing buffer, then resize this as needed. Most of this added complexity can be abstracted away through function calls should we desire to clean it up, but it should demonstrate the principle (more so than be a good example of why it’s preferable to do this here). This is most similar to a technique known as Arena allocation, and whilst I won’t cover/use that here (at least, not yet), I will leave some links for the reader to enjoy1 2 3.
It should also be noted that these programs are trivial, and in reality we could probably refuse to deallocate any allocations, and just let the OS handle that on exit (the ultimate garbage collector); but again, this is to demonstrate how you can choose to tackle a problem in a different way.
How The Lexer Handles Lifetimes
So in my lexer, I have not opted for the previously outlined method, at least in this case; instead, I opted to allocate a single buffer once, then create a struct which points into this buffer and gives us our view of a smaller subsection of the string.
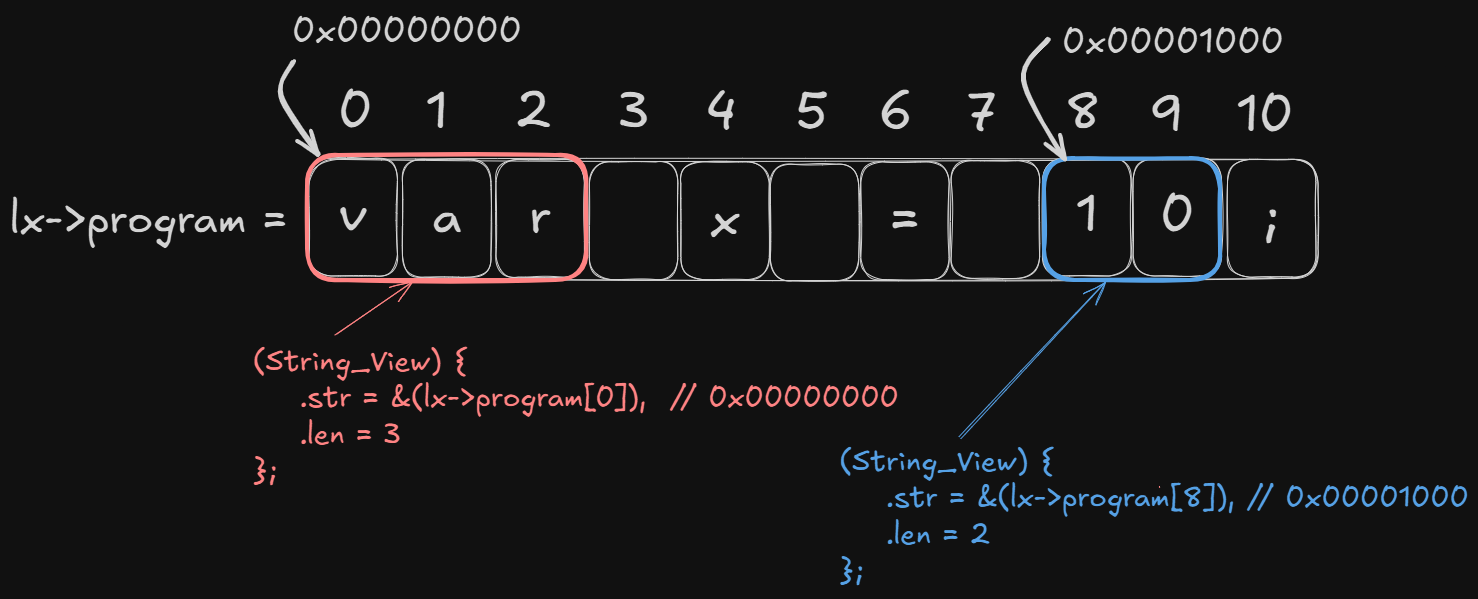
In this program, that structure is called a String_View.
As previously noted, this type is composed of a pointer,
and a length. The pointer points to some offset in Lexer.program, for example,
assume that program is defined as
var x = 10;
The first token, representing var, generated from here will have its String_View
defined as:
token.literal = (String_View) {
.str = &(lexer->program[0]),
.len = 3
};
And the token representing the integer literal 10 will have its literal defined
as:
token.literal = (String_View) {
.str = &(lexer->program[8]),
.len = 2
};
To better demonstrate what some of this pointer trickery is doing, here is an image showing the string as a char array, with each char assigned an index:
Encoding The Kind of Token
Token_Kind as previously mentioned is an eunm, which is defined as
typedef enum token_kind
{
#define X(NAME) TK_##NAME,
#include "defs/token-kind.def"
#undef X
} Token_Kind;
Now this probably looks like utter nonsense to most of you…
- Where are the enumerants?
- Why am I defining some obtuse macro which isn’t used?
- Why is immediatly
#undefed? - What on earth is the
includedoing there? - What is a
.deffile?
Simply put, this is a convienience I took to make my life easier, as the trick used
here is also used to help me write a to_string function for this enum. But to
discuss what is going on, and to appreciate the problem this solves, we need to
discuss the C Preprocessor.
The Preprocessor
For those unfamiliar with C/C++, particularly the compilation model let’s just cover that before we get to the details. The steps in compilation are as follows:
- Run the prepocessor - handle
#include,#define, and other such directives. - Compile a translation unit into an object file.
- Link all compiled object files, and any libraries, into the final executable.
A translation unit in this case, roughly, is a single C/C++ source file. This isn’t quite accurate, but it’s good enough working definition for our purposes.
But, we’re here to discuss the preprocessor, not the full compilation model.
A Crash Course
As mentioned, the preprocessor is the first step in compilation. What happens during
this is that a series of directives - defined as #<directive> - are enountered
whilst the translation unit is processed, and a textual replacement operation is
performed.
Take for example the following macro, part of a familiy called function-like macros:
#define MIN(A, B) ((A) < (B) ? (A) : (B))
Now assume that this is used in a statement int res = MIN(10, 5);, what happens
when the preprocessor runs is that MIN(10, 5) will be expanded to ((10) < (5) ? (10) : (5)).
This style of macro was more commonly used when compilers didn’t support function
inlining, but does come with the double edged sword of lacking type information; this
is good as now you have a “function” which works for all integral types and floats -
no need to define different functions for each type! - this does however mean that
you can end up with… less than helpful errors should you, for example, attempt
to compare some struct with an unsigned long.
With that, let’s move on to a cool technique, the one used to define the Token_Kind
enumerants…
X-Macros
X-Macros are a technique I only found out about quite recently, from listening to (and reading the comments on) an interview with Billy Basso (creator of Animal Well), which references a subsection of a GDC talk, The Simplest AI Trick in the Book.
They are a sanity saver! The technique leverages this property of C macros, and the preprocessor, namely that it is a textual substitution. Let us take a classic example of this, paired down for brevity, of describing the days of the week as an enum, and a function which generates a debug string:
enum week_day {
Monday = 0,
Tuesday,
};
const char *week_day_to_string(enum week_day d) {
const char *str;
switch (d) {
case Monday:
str = "Monday";
break;
case Tuesday:
str = "Tuesday";
break;
default:
break;
}
return str;
}
Now whilst this may not seem too bad, we have 2 places where the same list needs to be maintained, and as an artifact of how C is normally written, these will be in 2 different files; as a result, it is quite easy (without strict compiler warning enabled) to forget to update the enum cases in these 2 places, a problem which only gets worse the more locations
This is a bit of a headache, so let’s rewrite this using the X-Macros technique, and then explain what’s happening:
#define WEEK_DAY_LIST \
X(Monday) \
X(Tuesday)
enum week_day {
#define X(NAME) NAME,
WEEK_DAY_LIST
#undef X
};
const char *week_day_to_string(enum week_day d) {
const char *str;
switch (d) {
#define X(NAME) case NAME: str = #NAME ; break;
WEEK_DAY_LIST
#undef X
default:
break;
}
return str;
}
The code looks a little more concise, however it’s not apparent what is going on; lets dig into the enum and walk through the evaluation of this dense block:
Starting with
enum week_day {
#define X(NAME) NAME,
WEEK_DAY_LIST
#undef X
};
If we replace WEEK_DAY_LIST with the content it encodes:
enum week_day {
#define X(NAME) NAME,
X(Monday)
X(Tuesday)
#undef X
};
Now finally let’s substitute the X:
enum week_day {
#define X(NAME) NAME,
Monday,
Tuesday,
#undef X
};
What we have done is encode a way of describing large scale substitution of a pattern,
not too disimilar from our MIN macro from earlier. The key difference here, is
that we immediately undefine the macro (X) after invoking it; this means we can
“reuse” the macro for a different subsitution later.
The power of this becomes apparent as we apply the same substitutions to our to_string
function:
const char *week_day_to_string(enum week_day d) {
const char *str;
switch (d) {
#define X(NAME) case NAME: str = #NAME ; break;
WEEK_DAY_LIST
#undef X
default:
break;
}
return str;
}
Substituting WEEK_DAY_LIST
const char *week_day_to_string(enum week_day d) {
const char *str;
switch (d) {
#define X(NAME) case NAME: str = #NAME ; break;
X(Monday)
X(Tuesday)
#undef X
default:
break;
}
return str;
}
And substituting X:
const char *week_day_to_string(enum week_day d) {
const char *str;
switch (d) {
#define X(NAME) case NAME: str = #NAME ; break;
case Monday: str = "Monday" ; break;
case Tuesday: str = "Tuesday" ; break;
#undef X
default:
break;
}
return str;
}
The final transformation may look a little magic to those not seasoned with the
preprocessor weridness, the #NAME directive translates as “make this a string”.
From these 2 examples, the power and utility of this technique should be evident.
To dig a little deeper, one way in which we can make things cleaner is to pull the
WEEK_DAY_LIST out into a separate .def file (week-day.def) which looks something
like:
X(Monday) \
X(Tuesday)
And would mean we refactor our code accordingly:
enum week_day {
#define X(NAME) NAME,
#include "week-day.def"
#undef X
};
const char *week_day_to_str(enum week_day d) {
const char *str;
switch (d) {
#define X(NAME) case NAME: #NAME ; break;
#include "week-day.def"
#undef X
default:
break;
}
return str;
}
So in the case of the Token_Kind enum, if we take the definition:
typedef enum token_kind
{
#define X(NAME) TK_##NAME,
#include "defs/token-kind.def"
#undef X
} Token_Kind;
and peek inside the token-kind.def file (with some lines omitted for brevity):
X(EOF) \
X(ILLEGAL) \
X(LPAREN) \
...
X(VAR) \
X(PRINTLN)
The expansion of our enum results in
typedef enum token_kind
{
TK_EOF,
TK_ILLEGAL,
TK_LPAREN,
...
TK_VAR,
TK_PRINTLN,
} Token_Kind;
It should be noted that the whitespace separation won’t actually be there when the file is subject to preprocessing, it is added for readability, and you may encounter problems with your compiler if you have long expansions - something to do with a max line length amount being exceeded (not something I have encounterd, but is something I have heard and thought I’d pass it on).
Hopefully you can see why this is quite a powerful, and useful technique; I have linked some more resources on X-Macros in the footnotes, if you want some extra reading.45678
Lexing symbols
The set of symbols currently supported in the language include:
- Brackets/parens:
( ) [ ] { } - Punctuation:
; - Operators
- Assignment:
= - Arithmetic:
+ - * / - Logical:
! < > <= >= == !=
- Assignment:
This is the most boring part to talk about as it’s as simple, in most cases as:
case '(':
{
token.kind = TK_LPAREN;
} break;
In some cases, such as logical comparison operators (== != <= >=) you have to
do some extra checks, take for example the case of != vs !:
case '!':
{
if (lexer_peek_char(lx) == '=')
{
token.kind = TK_NOT_EQ;
token.literal.len += 1;
lexer_read_char(lx);
}
else
{
token.kind = TK_BANG;
}
} break;
These all require a little more work, mainly because we need to (1) perform an additional
advance of the lexer, (2) increment the length of the literal. Beyond that, if other
operators are added (such as +=) the existing operator handling code will need
to be updated to account for this.
Lexing Identifiers/Keywords
It is relatively trivial to deal with idents and keywords. For starters, under the default case of the lexer, we do the following:
default:
{
if (is_digit(lx->ch))
{ ... }
else if (lx->ch == '\"')
{ ... }
else if (is_char(lx->ch))
{
// NOTE(HS): ident/keyword/builtin parsing
size_t pos = lx->pos;
lexer_read_ident_or_keyword(lx);
size_t len = lx->pos - pos;
token.literal.len = len;
token.kind = string_view_to_token_kind(token.literal);
return token;
}
} break;
Lexing an identifier/keyword is defined simply to advance the lexer until some non alphanumeric character is encountered:
void lexer_read_ident_or_keyword(Lexer *lx)
{
while ((is_char(lx->ch) || is_digit(lx->ch)) && lx->ch != '\0')
{
lexer_read_char(lx);
}
}
Then, in order to determine whether the lexed ident it a keyword or not, we run it through a match function:
Token_Kind string_view_to_token_kind(String_View sv)
{
#define lexer_sv_cmp_str(SV, S) \
((strlen((S)) == (SV).len) && (strncmp((S), (SV).str, (SV).len) == 0))
Token_Kind kind;
if (lexer_sv_cmp_str(sv, "var")) { kind = TK_VAR; }
else if (lexer_sv_cmp_str(sv, "println")) { kind = TK_PRINTLN; }
else { kind = TK_IDENT; }
return kind;
}
The main thing to discuss here is the macro, which is just a fancy way of checking:
- the length of both the
String_Viewand the C-string are identical- if you have C-string
varand aString_Viewpointing tovariantthis preventsvariantincorrectly matching - I had issuses only checking this with
strncmp
- if you have C-string
- the actual byte-wise equality of the String_View and string
By default, if no keywords are matched, we assume it is an identifier.
Lexing Number Literals (Integers)
For now, the language only supports integer literals, so we will only deal with their
handling. Integers are lexed in the default case of the switch statement:
default:
{
// TODO(HS): impl float support
if (is_digit(lx->ch))
{
size_t pos = lx->pos;
lexer_read_number(lx);
size_t num_len = lx->pos - pos;
token.kind = TK_INTEGER;
token.literal.len = num_len;
return token;
}
...
} break;
The main function here is lexer_read_number, which is pretty simple:
void lexer_read_number(Lexer *lx)
{
while (is_digit(lx->ch) && lx->ch != '\0')
{
lexer_read_char(lx);
}
}
In essence, until a non-numeric character is encoutered (and if not end of input)
just keep advancing the lexer. As noted, there is no support for floats, I have a
few ideas on how to add that; there is also no support for alternate integer representations,
such as hex notation (0x10), binary (0b1010), or octal (0o12).
Lexing String Literals
Strings are also fairly trivial, however there are a few points of nuance, for instance
- should strings be definable by both single (
') and double (") quotes? - should string literals be stored containing the original quotes?
I have opted to make strings only definable in this language as by being surrounded by double quotes, and by not storing the source quote marks when the token representing the string is lexed.
Like integer, and idents/keywords, this is handled under the default case:
default:
{
...
else if (lx->ch == '\"')
{
// NOTE(HS): "consumes" the surroinding quotes as these aren't needed to store
// the fact this is a string
lexer_read_char(lx);
size_t pos = lx->pos;
lexer_read_string(lx);
size_t str_len = lx->pos - pos;
lexer_read_char(lx);
token.kind = TK_STRING;
token.location.pos = pos;
token.literal = (String_View) {
.str = token.literal.str + 1,
.len = str_len
};
return token;
}
...
} break;
Here we advance the lexer, “consuming” the opening quote mark, prior to lexing the
output string. Then we call the major function for string processing lexer_read_string.
Finally we advance the lexer again to consume the closing quote mark. From this,
much like lexing integers and idents/keywords, we can calculate the size of the token
literal by subtracting the start point of the lexer from the end. It should be noted
that the way I chose to do it is one way this could be done, we could derive the
length after consuming the closing quote, this would just require us to fudge the
number by subtracting 1; personally I prefer this approach, it’s more symetric with
the consume quote -> read -> consume quote method I have implemented in the other
default cases.
The function lexer_read_string is quire similar to that of integers, with a few
modifications:
void lexer_read_string(Lexer *lx)
{
while (lx->ch != '\"' && lx->ch != '\0')
{
if (lx->ch == '\\' && lexer_peek_char(lx) == '\"')
{
lexer_read_char(lx);
}
lexer_read_char(lx);
}
}
One such modification is handling the escaped chars, sort of. The extent of this
is to handle \' and \" chars, the handling of \" in particular is to ensure
that strings are not prematurely terminalted. This escape sequence handling is hardly
comprehensive; the following set of chars is not handled and at some point should
be \\, \n, \r, \t, \b, \f, \v, \0.
Handling All Other Input
Finally we have a catchall case, which is an incredibly blunt tool in this first pass, it could possibly be improved but I don’t want to deal with that until I have some actual usage examples of this language. When I say blunt, the code for handling all other input is
default:
{
...
else
{
token.kind = TK_ILLEGAL;
}
...
} break;
That’s it. Just set the kind to ILLEGAL, and continue. Now this isn’t something
covered in the test cases, mainly because I don’t want to define illegal inputs in
the test, since there will be a lot of changes comming in the future, this also is
meant (really) to be a flag that “hey something unexpected was found here” for some
diagnostics.
Integrating The Lexer
Now for something a little less dry, mainly as we can finally see a more dynamic response than just the tests pass… We’re creating a simple REPL! For now this is just going to take our input, and perform lexical analysis on it, echoing the tokens to the terminal.
Reading User Input - The Traditional C way
There are a handful of ways of reading user input in C, one (and the oldest) is
gets. The manpage for gets9 reads Never use gets()10 as it reads
into a buffer until a null-terminator (\0) is encountered. This can be problematic
as there are no bounds checks performed on the supplied buffer, potentially resulting
in buffer overruns (which can lead to a whole series of problems). As a result, this
function will not be used.
Safely Reading User Input
There are a few ways available to us, depending on requirements, but the REPL constructed
here will use fgets.11
char* fgets( char* restrict str, int count, FILE* restrict stream );
This defines a function which takes a buffer to read input into, the size of the
buffer (to perform bounds checks, reading at most count-1 bytes), and the source
file stream to read from11. Something else to note about this function is that
it will stop parsing when a newline char (\n) is encountered, and the string will
contain the newline; parsing also stops if EOF is encountered.
This is not amazing, but will suffice for now - this mainly is annoying as you can’t
split statements over multiple lines. If I decide to implement this later, then I
might check out getchar12, coupled with my own bounds checking. I may also be
able to get this behaviour with fgets, but I will need to do some experimentation
to see what works.
Hooking It All Up
We know how to get user input, we have our function to tokenise input, all we need
to do is hook this up so a user can run the program and get some feedback! The design
decided on was eventually a single function call from main:
void repl_run(void)
{
while (true)
{
fprintf(stdout, "tyger> ");
char input_buffer[REPL_INPUT_BUFFER_SIZE];
memset(input_buffer, '\0', sizeof(input_buffer));
if (!fgets(input_buffer, sizeof(input_buffer), stdin))
{
fprintf(stderr, "[ERROR]: Error getting user input from stdin\n");
break;
}
Lexer lexer;
lexer_init(&lexer, input_buffer);
Token token;
while ((token = lexer_next_token(&lexer)).kind != TK_EOF)
{
char token_str[512];
token_to_string(token, token_str, sizeof(token_str));
fprintf(stdout, " %s\n", token_str);
}
}
}
This function:
- prints a prompt to the user
- creates a buffer on the stack and calls
memsetto zero the array - attempts to read user input into the buffer
- initialise the lexer on the stack
- call
lexer_next_token - compare the kind of token to check if end of input reached
- stringify the token
- echo the string to
stdout
Then to make this available to the user, just add the following to main.c
#include "repl.h"
int main(void)
{
repl_run();
}
With all that, when we call our executable, we now get the following:

It should be noted that in some of the example usage of fgets I have seen the
following line added, to remove the newline:
if (fgets(buffer, sizeof(buffer), stdin) != NULL) {
// Remove newline character
buffer[strcspn(buffer, "\n")] = 0;
...
}
In our case this is not important, since we just consume all whitespace anyway, and it has no signigicance in the language (this may be important later when the REPL is expanded, but can be ignored for now).
Closing Thoughts & Further Updates
There’s still a lot of ground to cover, but I think this is a solid foundation to build on. One of the areas lacking at the moment is appropriate error handling, for now the code is just littered with asserts, which in and of itself is not bad, but some asserts may be recoverable errors. I will be looking into alternative error handling methods later, during the next section, parsing.
- Repo: https://github.com/hshakeshaft/tyger
- Final Commit for entry: fd3c376
- Series Page following development