Tyger 2 Parsing
Slaying the Dragon
This post is part of a series, click here to read more.
We left off last time with a (mostly) functioning lexer; as developments laid out here revealed I left a few things unimplemented which should have been, for example the lexer didn’t support commas, which made for a fun bug discovery later (when parsing function calls). But that’s us getting ahead of ourselves, what we’re concerned with now is the act of parsing the lexed tokens into something with meaning; i.e. generating an AST (Abstract Syntax Tree).
If you’re like me and have taken a few stabs at implementing a language, then you may have found the topic of parsing complex; some of this is due to the diverse set of methods you can approach this with. Many examples I’ve seen all “default” to using parser generators, which I’m sure are fine and have their place in the space, I however think implementing things yourself is quite useful (and I’ve never liked the hand-waving response of “just do this and don’t worry about the details”). So hopefully this works as a good explanation of Pratt Parsing, and also shows how one may want to design a solution to the problem in C.
The Structure of A Tyger Program
Programs are a collection of 1 or more statements. Each statement is one of either a variable declaration statement, or an expression statement. Expression statements are, to be pithy, statements wrapping expressions; these only really exist as the following examples are valid statements within the language:
"Hellope!";
1015;
5 + 4 - 2 * 3 / 1;
With that said, what is an expression in this language? In short, anything which
produces a value. To be more explicit, integers, strings, function calls, and operations
containing some infix operator (+ - * /) are all expressions. Now as noted in
part 1, this is a radically pared
down version of what I want the final language to be, so undoubtedly the range of
available kinds of statements and expressions will grow to meet the changing scope
of the language.
This however is good enough to begin the process of parsing our lexical output into an AST, which itself will later be evaluated.
Setting Up The Parser
In order to parse programs, there needs to be some data structure, much like for the lexer. Our parser, again, is derived from the book, and as such looks (near) identical:
typedef struct parser
{
Lexer *lexer; // an instance of the lexer
Token cur_token; // the token the parser is currently inspecting
Token peek_token; // the next token the parser will look at
} Parser;
The extent of the “public” API to use the parser is then the following 2 functions:
void parser_init(Parser *p, Lexer *lx); // performs correct initialisation of the parser
Program parser_parse_program(Parser *p); // generates our "program" struct as a result of parsing
These should be self-explanatory, and only the internals obscured (they aren’t that
interesting at the moment anyway). The Program struct returned by our function
is defined as
typedef struct program
{
Statement_VaArray statements;
Error_VaArray errors;
Parser_Context context;
} Program;
This struct comprises the following members:
- 2 dynamic arrays, 1 for the program statements and another for the errors
- some Context object; for now this can be treated as entirely opaque as it’s not yet important.
A fairly simple series of data structures, now how the parser transforms the input into the final program is through the following steps:
- Check if
Parser::cur_tokenisEOF - If so, we have generated our program
- Else, until
EOFis reached repeatedly callparse_statement- Once statement is parsed, if any errors encountered, add them to add errors array
- Else add the statement to the array of statements
And parsing a statement comprises:
- Match
Parser::cur_token - If
kindisTK_VAR(i.e. the var keyword)parse_var_statement - Else, for all other token kinds, attempt to
parse_expression_statement
All relatively straightforward, at least from a high level. But before covering Pratt Parsing, I will quickly detour to talk about some useful testing and debugging features I implemented for myself.
Testing and Debugging
Printing The AST
It’s all well and good saying that after parser_parse_program is called there’s
now a program there; it is however much harder (again without running it) to be
able to verify the correctness of the parse result (i.e. the shape of the AST)
in absence of just inspecting memory addresses in a debugger. This is impractical
as soon as the program become more complex than 10;, so a better solution is
required.
As a result, I decided to take a(nother) idea from the book and write a little internal utility for me to transform any given (parsed) program into a string form, containing the nuances of the parsed result (such as operator precedence) and then use this generated string in my comparison functions. This in particular proved useful for rigorous operator precedence testing, and for comparisons of items such as idents.
The API I came up with can be found under the trace.h file; this is relatively small, consisting of a single function call and an enum representing the output format:
typedef enum trace_format
{
TRACE_YAML,
TRACE_SEXPR,
} Trace_Format;
const char *program_to_string(const Program *p, Trace_Format format);
The 2 formats supported are YAML and SEXPR, the former should be obvious, but
the latter is meant to be like an S Expression.
For example, the following table shows how some different programs may be converted
into the following S-expression syntax
| Program | S-Expression |
|---|---|
var x = 10; |
(var x 10) |
"Hello, World!"; |
("Hello, World!") |
10; |
(10) |
1 + 4; |
((+ 1 4)) |
10 + 5 - 4 * 3 / 2; |
((- (+ 10 5) (/ (* 4 3) 2))) |
The last 2 rows look a little strange with the extra parentheses, this is mainly an artifact of not being able to find a more elegant solution to guaranteeing that representations of s-expression style infix expressions were always surrounded by parentheses (particularly when either nested or appearing as a function call arg).
It should be evident that, particularly in the case of the last, that this is better than just writing the individual, unrolled assertions (particularly in a generic way which can be “table driven” for testing). The way this would look, for the 4th option would be
TEST(Parser_Tests, Parse_Infix_Expression)
{
// input: "1 + 4;"
// setup for generating the program here
Expression *expr = prog.statement.expression_statement.expression;
ASSERT_EQ(expr->kind, EXPR_INFIX);
ASSERT_EQ(expr->lhs->kind, EXPR_INT);
ASSERT_EQ(expr->lhs->int_expression.value, 1);
ASSERT_EQ(expr->rhs->kind, EXPR_INT);
ASSERT_EQ(expr->lhs->int_expression.value, 4);
}
It should probably be noted, that the expanded version of the final table exaple, when represented as a tree, is
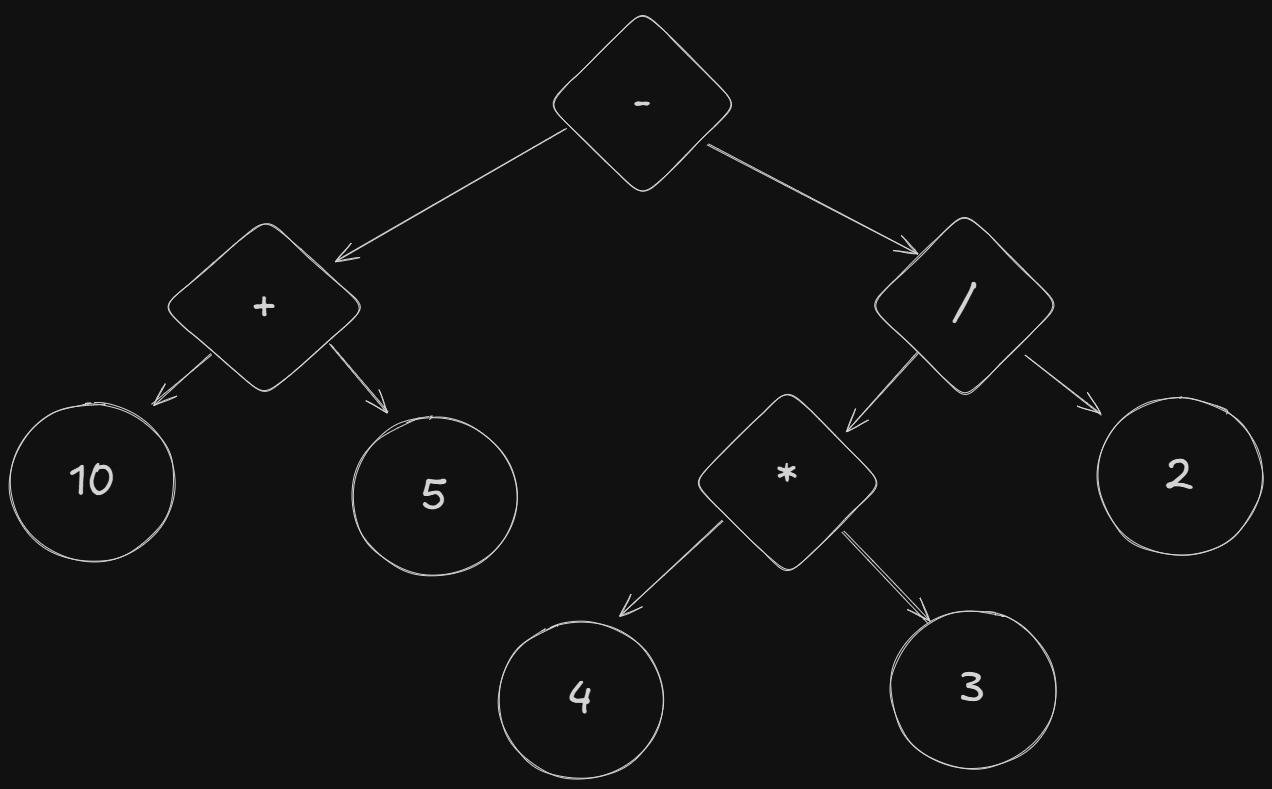
Imagine writing all the asserts for that!
The YAML output format is a more structured format, and also includes some additional debug information per node in the AST. Take the simple example of
var x = 10;
This is transformed into
---
Errors: 0
Statements: 1
---
program:
- kind: VAR
ident: x
expression:
- kind: INT_LITERAL
value: 10
And the statement var foo = 1 + 2 - 3 * 4 / 5; becomes
---
Errors: 0
Statements: 1
---
program:
- kind: VAR
ident: foo
expression:
- kind: INFIX
op: "-"
lhs:
- kind: INFIX
op: "+"
lhs:
- kind: INT_LITERAL
value: 1
rhs:
- kind: INT_LITERAL
value: 2
rhs:
- kind: INFIX
op: "/"
lhs:
- kind: INFIX
op: "*"
lhs:
- kind: INT_LITERAL
value: 3
rhs:
- kind: INT_LITERAL
value: 4
rhs:
- kind: INT_LITERAL
value: 5
Testing Utilities
One thing I thought would be useful in my C++ code, as it is in other languages
I have used, is a defer keyword. In languages such as Go, there exists a keyword
defer which basically means “run this statement/block later”; this doesn’t exist
in C++, however this can be implemented using some “more modern” (C++11) features.
Specifically, defer can be implemented using lambdas, and embracing C++’s
deterministic object lifetimes (i.e. RAII). Now I should note that the implementation
I used, is cloned from a blog post1
by one of the developers from the game The Witness.
To start, C++11 added support for lambdas, which allows you to define local functions within larger functions (for example), or even pass them to as parameters to functions. To leverage this in testing, it is possible to create a (template) class, have this take in a lambda as a constructor parameter, then call said lambda in the destructor:
template <typename F>
struct ScopeExit
{
ScopeExit(F t_f) : f(t_f) {}
~ScopeExit() { f(); }
F f;
};
So this works something like
void log(int level, const char *message)
{
auto buffer = new char[256];
ScopeExit([=]() { delete[] buffer; }); // object constructed here, with lambda
if (level < 30) {
return;
} // if `level < 30` then ~ScopeExit() runs, and the lambda
int bytes = std::snprintf(NULL, 0, "[INFO] %s\n", message);
std::snprintf(buffer, bytes + 1, "[INFO] %s\n", message);
buffer[bytes] = '\0';
std::cout << buffer;
} // ~ScopeExit() runs here, and the lambda
As can be seen in this example, there are 2 different exit points, after a conditional
fires and at the end of the “happy path”. Without ScopeExit, you have to remember
to put the corresponding delete[] call in 2 different places, and the more places
you need to cover, the more likely you miss something. You can also get more complex
“teardown” processes, this is partly why RAII became desired as a language feature;
it provides deterministic lifetimes for objects, and in this case, this temporary
buffer is (now) guaranteed to be deleted whenever the function exits.
The rest of the code is designed to offer a prettier wrapper around the object:
template <typename F>
ScopeExit<F> MakeScopeExit(F f)
{
return ScopeExit<F>(f);
}
#define DO_STRING_JOIN(S1, S2) S1 ## S2
#define STRING_JOIN_2(S1, S2) DO_STRING_JOIN(S1, S2)
#define DEFER(...) \
auto STRING_JOIN_2(defer_scope_exit_, __LINE__) = MakeScopeExit([=] () { __VA_ARGS__ })
MakeScopeExit is a wrapper which constructs the object with the correct type,
and DEFER is the actual macro in use.
Pratt Parsing
Pratt parsing, described by Vaughan Pratt
in a 1973 paper Top Down Operator Precedence2, is a parser technique based
on recursive descent parsing. These are parsers which operate in a top-down fashion,
meaning they define the start symbol as the root and move down to define terminal
symbols at the bottom; the recursive part means that until terminal nodes are found
in the tree the parser will call other procedures, possibly recursively; for example,
when parsing expressions, one continually calls parse_expression until a leaf
is encountered, such as a value expression, like an integer.
This can be a little abstract and hard to see what it means; don’t worry, I definitely felt that when first going over this - and the next 2 times as well! (yes I have started and stopped this a few times). As a result, I think it’s best that I show some examples and embrace the notion of a picture says 1000 words; but before that, I’m going to discuss the high level mechanism of parsing before the actual recursive descent part.
Parsing Var Assignment Statements
At time of writing, there are 2 kinds of statements present in Tyger, Var statements,
and Expression statements. We’ll cover Var statements only for now. In Tyger,
a Var statement is defined as a statement beginning with the keyword var, followed
by any ident (e.g. foo), then an assignment (to an expression). In other words,
this is defined in the following struct:
typedef struct var_statement
{
const char *ident;
Expression *expression;
} Var_Statement;
And Expression is defined as
// Forward declaration as size unknown and need to ref with pointers in other expressions
typedef struct expression Expression;
// ... concrete expression union kinds ...
struct expression
{
Expression_Kind kind; // An enumerant representing the kind of expression (like Token_Kind)
uExpression expression; // A union of all the different kinds of expressions, opaque for now
};
Note that if you look at the definitions within parser.h these structs differ (in part) from what is actually in the repo. This is simply because the internals for how storing and accessing expressions (in particular) were drastically refactored from when I first wrote the parser code; this is all stuff which will be explained later on.
But taking a step back, how is this actually handled at the level of parser_parse_program?
Well, that function looks like:
Program parser_parse_program(Parser *p)
{
Parser_Context ctx;
// initialisation of structs ...
Program program = {0};
// initialisation of structs ...
while (p->cur_token.kind != TK_EOF)
{
Statement stmt = {0};
Tyger_Error err = parser_parse_statement(p, &ctx, &stmt);
// if error, store the error, else store the statement
parser_next_token(p);
}
// misc post-processing
return program;
}
This function just runs until EOF is encountered, and repeatedly calls parser_parse_statement.
I will omit an explanation of what Tyger_Error is for now, and cover it later
The parser_parse_statement function looks like:
Tyger_Error parser_parse_statement(Parser *p, Parser_Context *ctx, Statement *stmt)
{
Tyger_Error err = {0};
switch (p->cur_token.kind)
{
case TK_VAR:
{
err = parse_var_statement(p, ctx, stmt);
} break;
default:
{
err = parse_expression_statement(p, ctx, stmt);
} break;
}
return err;
}
I.e. if TK_VAR (the var keyword) is encountered whilst parsing, the program
will attempt to parse a variable assignment statement. Rather than just dump the code
for parsing var statements, I will lay out the steps, and then show the code with
some omissions for brevity (especially as a lot of the code is error handling, or
“ceremony” for the internals):
- enter
parse_var_statement expect_peekthat the next token is anIDENT(i.e.parser::peek_token.kind==TK_IDENT)- store the value of
TK_IDENT expect_peekthat the next token isTK_ASSIGN- if
peek_tokenisTK_SEMICOLONreturn syntax error - call
parse_expression - if
peek_token_isthat the next token isTK_SEMICLONread over the semicolon - write statement members to out parameter
Before dumping the annotated function here, I should explain what expect_peek
and peek_token_is are; they are utility functions for testing the kinds of tokens
so that I don’t have to keep writing if (token.kind == <token kind>) { ... };
again, another idea from the book.
static inline bool peek_token_is(Parser *p, Token_Kind kind)
{
return p->peek_token.kind == kind;
}
static inline bool expect_peek(Parser *p, Token_Kind kind)
{
if (peek_token_is(p, kind))
{
parser_next_token(p);
return true;
}
else
{
return false;
}
}
Meanwhile, the (annotated) parse_var_statement function is defined as:
Tyger_Error parse_var_statement(Parser *p, Parser_Context *ctx, Statement *stmt)
{
// 1. enter function
Tyger_Error err = {0};
// 2. expect the next token is an ident
if (!expect_peek(p, TK_IDENT)) { /* return error */ }
// 3. store the ident
// ...
// 4. expect the next token is `TK_ASSIGN` (`=`)
if (!expect_peek(p, TK_ASSIGN)) { /* return error */ }
// 5. if `peek_token` is `TK_SEMICOLON` return error
if (expect_peek(p, TK_SEMICOLON)) { /* return error */ }
// 6. parse expresion
// ...
err = parse_expression(p, ctx, &expr, PRECIDENCE_LOWEST);
// ...
// 7. if peek_token is `TK_SEMICOLON` read it
if (peek_token_is(p, TK_SEMICOLON))
{
parser_next_token(p);
}
// 8. write statement out parameter
stmt->kind = STMT_VAR;
stmt->statement.var_statement = (Var_Statement) {
.ident = ident,
.expression = expression,
};
return err;
}
Again, the current iteration of the code is different to that present in the actual parser, because of some internal refactoring that came later. The difference is not important for now.
Parsing Expressions
The central part of Pratt parsing, parsing expressions. The kinds of expressions available in the language (at time of writing) are:
- Integer Expressions - producing integer values (
1,5,100) - String Expressions - producing string values (“Hellope!”, “the quick brown fox jumps over the lazy dog”)
- Infix Expressions - all binary arithmetic operations (
1 + 5and1 * 7 - 3) - Ident Expressions - calls to existing, bound, identifiers, (
var x = 10; x;) - Call Expressions - function calls (
println("Hello, World!");)- albeit this only really supports the
printlnbuiltin (for now)
- albeit this only really supports the
So, the expression parsing code is defined as this:
static Tyger_Error parse_expression(Parser *p, Parser_Context *ctx, Expression *expr, int precidence)
{
Tyger_Error err = {0};
switch (p->cur_token.kind)
{
case TK_INTEGER:
{
err = parse_int_expression(p, expr);
} break;
case TK_STRING:
{
err = parse_string_expression(p, ctx, expr);
} break;
case TK_IDENT:
{
err = parse_ident_expression(p, ctx, expr);
} break;
case TK_PRINTLN:
{
err = parse_call_expression(p, ctx, expr);
} break;
default:
{
Token_Kind k = p->cur_token.kind;
fprintf(
stderr, "[ERROR] Unexpected token kind encountererd whilst parsing: %i (%s)\n",
k, token_kind_to_string(k)
);
assert(0);
} break;
}
if (err.kind == TYERR_NONE)
{
while (!peek_token_is(p, TK_SEMICOLON) && (precidence < peek_precidence(p)))
{
parser_next_token(p);
err = parse_infix_expression(p, ctx, expr);
if (err.kind != TYERR_NONE)
{
return err;
}
}
}
return err;
}
All called functions within parse_expression are defined as returning an error
object, and all write their results (on success) to the expr out parameter. There
is also just an assert included under the default to crash in case some unsupported
token is found; this is a source for future improvement in error reporting.
But to explain the function, if either a “value producing” token is encountered -
defined as ints, strings, or idents - then the parser functions for those nodes
are called, and I will leave their explanation as they are fairly simple to understand.
Once the function parses these leaf nodes, a check is done where if, and only if,
the current “precedence” of the expression is lower than the next one, parse_infix_expression
is called, which itself will make a call to parse_expression (enter the recursion).
Precedence
You are probably familiar with operator precedence, the idea that certain operations should be carried out in a certain, defined order; you probably also learned some acronym to go along with this in your maths classes (in my case this was BIDMAS - brackets, indices, divide, multiply, add, subtract). Whilst precedence in this case is not exactly the same, we can still encode the order of operations in code, this is also how we encode how evaluation will be carried out later.
The precedence in the parser is defined, simply, as an enum:
enum {
PRECIDENCE_LOWEST = 0,
PRECIDENCE_EQUALS = 10, // ==
PRECIDENCE_LESSGREATER = 20, // > or <
PRECIDENCE_SUM = 30, // +
PRECIDENCE_PRODUCT = 40, // *
PRECIDENCE_PREFIX = 50, // -X or !X
PRECIDENCE_CALL = 60, // myFunction(X)
};
So in this case, the expression 5 + 4 * 3 should be parsed as 5 + (4 * 3).
Now, with this we can unpick a worked example (of 5 + 4 * 3), when parse_expression_statement
executes, it calls parse_epxression with precedence of PRECIDENCE_LOWEST. That
means that, when we call parse expression, can think of the following being the
case when we enter the loop:
// ...
// expr = { .kind = EXPR_INT, .expression = { .int_expression = { .value = 5 } } }
//...
while (!peek_token_is(p, TK_SEMICOLON) && (precidence /* PRECIDENCE_LOWEST */ < peek_precidence(p /* PRECIDENCE_SUM */)))
{
parser_next_token(p);
err = parse_infix_expression(p, ctx, expr);
if (err.kind != TYERR_NONE)
{
return err;
}
}
// ...
What this means is that until either a semicolon is encountered, or until the
current precedence exceeds or is equal to that of the precedence of the next token,
repeatedly call parse_infix_expression (which itself will call parse_expression);
this guarantees that we can parse arbitrarily long expressions, such as 1 + 2 + ... + 98 + 99 + 100.
The strangest looking part of this is why is expr, the out-param we just overwrote
in the preceding lines, being passed into parse_infix_expression as an inout-param
itself, therefore overwriting its value? Looking at the code:
Tyger_Error parse_infix_expression(Parser *p, Parser_Context *ctx, Expression *expr)
{
// ... Explanatory Comment ...
Tyger_Error err = {0};
int precidence = precidence_of(p->cur_token.kind);
Operator op = token_kind_to_operator(p->cur_token.kind);
parser_next_token(p);
Expression_Handle lhs_handle = va_array_next_handle(ctx->expressions);
va_array_append(ctx->expressions, *expr);
Expression rhs;
err = parse_expression(p, ctx, &rhs, precidence);
if (err.kind != TYERR_NONE)
{
return err;
}
Expression_Handle rhs_handle = va_array_next_handle(ctx->expressions);
va_array_append(ctx->expressions, rhs);
*expr = (Expression) {
.kind = EXPR_INFIX,
.expression.infix_expression = (Infix_Expression) {
.op = op,
.lhs = lhs_handle,
.rhs = rhs_handle,
}
};
return err;
}
The strangest looking part of this may be why we pass expr, the out param we just
overrode into parse_infix_expression. We pass this in because this is the left-hand side
(LHS) of our infix expression, and let parse_infix_expression handle the copying
of the data into our Parser_Context::expressions dynamic array. This param is then
later overridden to become an infix expression which is our return value (on success).
When parse_infix_expression is called, the following happens:
- the precedence of the current operator is taken
- a handle to the left-hand side (LHS) of our infix expression is generated
- the value of
expris copied into theParser_Context::expressionsdynamic array - a new expression is created on the stack
- this is passed to another call to
parse_expression, using the precedence derived in 1 - when this returns, a handle to the right-hand side (RHS) of our infix expression is generated
- the value of
rhsis copied into theParser_Context::expressionsdynamic array - the
inparam,expr, is then overridden, and becomes an out param, defining our new infix expression
The magic of this is, if we carry on until a lower precedence operator, or a semicolon is met, it will result in successive rewrites of the underlying AST.
Worked Example 1
Take the example 5 + 4 * 3; - this will first generate the following infix expression:
pass 1:
(+)
/ \
5 4
Then, because the * operator hash higher precedence than +, we pass 4 into
another call to parse_infix_expression where we generate the following tree:
pass 2:
(+)
/ \
5 (*)
/ \
4 3
The RHS of the AST from pass 1 is rewritten to be another infix expression,
containing our multiplication, which will be evaluated before our + 5.
Worked Example 2
Take however another example, 3 * 4 + 5; (the mirror of the former); after the
first pass we have this as our expr:
pass 1:
(*)
/ \
3 4
Hopefully this isn’t shocking, but when we call parse_expression on the RHS of
this tree (i.e. on 4), since * hash higher precedence than +, we return this
expression as our result, then continue the loop in the initial call to parse_infix_expression,
this time passing in the result of pass 1 as the left-hand side of our expression.
This then generates:
pass 2:
(+)
/ \
(*) 5
/ \
3 4
Which again is correct; the deeper nesting of 3 * 4 will be evaluated before summing
with 5.
Worked Example 3
Take 1 * 5 + 4 * 2 / 1;:
First, we parse 1, then encounter *, subsequently we generate this subtree:
(*)
/ \
1 5
Precedence of * is greater than +, so we return and start parsing the right-hand
side of +, since precedence of * is the same as that of /, the statement returns
after parsing 4:
(+)
/ \
/ \
(*) (*)
/ \ / \
1 5 4
Finally, the expression 2 / 1 is parsed, and we end with:
(+)
/ \
(*) \
/ \ \
1 5 (*)
/ \
4 (/)
/ \
2 1
An Aside
I hope that makes sense - spent quite a bit trying to figure out some good explanations, and visual aids, to help demonstrate the point - maybe I’ll revisit this idea in another post with some animations (if I ever learn how to use available tools). This is also something I wanted to touch on, there was a gap between writing this post and the actual completion of work - mainly because I got stuck on this explanation and I think used it - initially - as an excuse to not finish the article. This did lead to some extra fun when picking it back up as I had to unpick this memory model again of what was going on. (I will also be honest - I got sidetracked on other projects and left this alone for a few months.)
Once again, I would like to stress the importance of having a decent debugging tool, and in this case developing the S-Expression based debug strings was a life-saver; imaging trying to watch all this correctly shuffling data via pointers in a debugger’s watch window! Even though their development (seemingly) saps from the main goal, and the fun stuff, it is time well invested if it is a useful tool, hence why I also wanted a more structured AST representation in YAML, YAML for me, S-Expressions for the test framework.
But that’t it really, Pratt parsing, and handling operator precedence; not actually too bad, and I hope that this has helped cement it in your mind, if not go play with the code or draw out your own diagrams and build your AST from these nodes!
Parser Context
Now, on to some more technical details of the parser, more the “nuts & bolts” of how things work - first up, context args.
Other languages, such as Go, Odin, and JAI (not publically available, and not
something I’ve had a change to play with) have an implicit function arg, called context.
Depending on the language, this is either a map or a struct, which can be overridden
or extended by the programmer. The point of this parameter is a way to bundle extra
parameters into the scope of the function without having to explicitly pass them -
in Odin for example, the context contains the default (heap) allocator of the
language, which is used by all “new” and “delete” style operations (and can be overridden
to provide custom allocator functionality).
I decided I wanted a similar concept for C, for at least this problem, i.e. requiring
somewhere to store all and expression data which was not just in arbitrary many
desperate heap locations (which becomes a nightmare to untangle and ensure correct
resource cleanup later). I did think about two approaches as for how the context
could be passed to functions; on one hand I could pass a separate parameter, which
means adding yet another parameter to all function calls, and on the other hand bundling
context alongside the Parser struct. Ultimately, I opted for supplying a second
argument, primarily because this is simpler than having to handle the handover of
ownership at the end of parsing from the parser to the program, or (potentially)
worse, copying all data - which is just wasteful if it’s all there!
I should also explain why I saw need for this context struct in the first place. Given some of my comments in the previous entry in this series about making lifetime management of objects in C as easy and simple as possible, I foresaw quite early on the fact that I would need some backing memory buffer where I could store all data generating during parsing such that I would not have to handle the, rather hairy, lifetime soup that comes from performing multiple, arbitrary heap allocations, not to mention any cleanup efforts that come later when deallocating all resources.
To facilitate this I chose to implement a series of dynamic array, referred to
throughout the code as va_arrays (for variable arrays, as opposed to static arrays).
I will address what those are next, but in short, for those more familiar with C++
think std::vector, or in Java think ArrayList, i.e. some kind of resizable array.
The Parser_Context struct is defined as:
typedef struct parser_context
{
String_VaArray identifiers; // Identifiers that appeared in `var` statements
String_VaArray evaluated_identifiers; // Identifiers which are to be evaluated for a value
Expression_VaArray expressions; // Contains all expressions generated during parsing
String_VaArray strings; // contains all string data, the sereis of bytes
} Parser_Context;
The reason for separating the identifiers is superfluous, and reflecting on why it’s
this way, I can’t think of a reason other than lower mental overhead whilst writing.
This is something else to revisit at a later date, there may be something I’m forgetting
whilst writing as to why they need to be separate, but would otherwise be a simple
refactor. What exactly each VaArray is defined as is not worth going into on a
per-case basis, so I will leave the reader to read the source
if he wants more “insight” (but this is all about to be covered anyway).
Dynamic Arrays (In C)
Yes, dynamic arrays can be implemented in C, they aren’t exclusive to C++, Java,
or Python! They are phenomenally simple, at least in my implementation, now what you
may have noticed is that there are several seemingly desperate VaArray types. C
unfortunately does not have generics, and if you attempt to cajole them into the
language though use of void* compilers tend to hate you, so I opted for an easier
but less simple technique, leverage the preprocessor to define interfaces over which
a series of operations can work.
Any dynamic array can be expressed as a struct with at least the following fields:
struct Va_Array
{
T *elems; // pointer to the buffer containing elements of type T
size_t capacity; // the capacity of the array, i.e. how many elements it **can** hold
size_t len; // the number of elements the array **does** hold
};
Since we know that all dynamic arrays conform to this interface, we can define a macro which performs our operations, such as initialisation:
#define va_array_init(T, DA) \
do { \
(DA).capacity = 32; \
(DA).len = 0; \
(DA).elems = malloc(sizeof(T) * (DA).capacity); \
} while (0)
So for example, to initialise a va_array of expressions we would write:
Expression_VaArray expressions = {};
va_array_init(Expression, expressions);
This is an imperfect system, mainly as it requires working with macros which just get annoying to work with over longer, more complex functions; there’s also the whole lack of typing inherent in the preprocessor but eh, an inconvenience worth living with for convenience (also it seems you can just debug once and then it more or less works without issue).
This is all well and good, but what happens when we append elements?
#define va_array_append(DA, ELEM) \
do { \
if ( (DA).len + 1 > (DA).capacity ) { \
size_t new_capacity = (DA).capacity * 2; \
void *new_buffer = realloc((DA).elems, new_capacity); \
if (new_buffer != (DA).elems) { \
(DA).elems = new_buffer; \
} \
(DA).capacity = new_capacity; \
} \
memcpy( &((DA).elems[(DA).len]), &(ELEM), sizeof((ELEM)) ); \
(DA).len += 1; \
} while (0)
Firstly, we must check if the addition of a new element will overflow the capacity.
If yes, we need to allocate a new buffer with enough space for all previous elements,
plus the one, ideally with enough headroom for us to be able to allocate many more
entities before we need to allocate space again. Then after allocating the new space,
we must copy all elements from the old buffer to the new, and free the old. I chose
to just use realloc under the hood as it means I (personally) have to care less
about manually copying the bytes into a new buffer (and freeing the old). The full
suite of “functions” I implemented for dynamic arrays can be found in the repo.
You do also need to pick a “sensible” scaling factor to regrow your array by each
time you exceed the capacity, the reason for this is it’s slow to go out to the OS
and have it provision memory for you to use (via malloc), so we ideally want this
minimised. I chose to just double the capacity every time it gets exceeded; this
may be a more wasteful strategy, but I think the reduction in allocations is a worth
the cost.
The major benefit here, as with arenas[^20] is I now have a single block of objects
(of shared type), all bundled under a single pointer, which makes cleanup as easy
as free(<va-array>->elems)! Now I should come on to where this attempt to simplify
my life actually caused some headaches…
Handles Vs Pointers
Earlier on I made reference to taking handles to the Parser_Context::expressions
array; this may have seemed hand wavy and that was intentional. Initially, the struct
for a String_expression, for example, was defined as such:
typedef struct string_expression
{
const char *value;
size_t len;
} String_Expression;
And the function parse_string_expression looked something like this:
Tyger_Error parse_string_expression(Parser *p, Parser_Context *ctx, Expression *expr)
{
Tyger_Error err = {0};
const char *str_value = &(ctx->strings.elems[ctx->strings.len]);
va_array_append_n(ctx->strings, p->cur_token.literal.str, p->cur_token.literal.len);
va_array_append_n(ctx->strings, PARSER_NULL_TERMINATOR, 1);
*expr = (Expression) {
.kind = EXPR_STRING,
.expression.string_expression = (String_Expression) {
.value = str_value,
.len = p->cur_token.literal.len
}
};
return err;
}
Don’t be put off by va_array_append_n - this is just a way to copy N elements
into the dynamic array (only really exists for copying strings). What is important
is can you spot the bug in this code? Nor could I when I wrote this. Worse, it didn’t
even rear its head until I started fleshing out string parsing test cases later
on in development! The bug I saw was that, when I tried parsing some strings,
seemingly those where the length of was greater than 32 chars, I would start
encountering “heap corruption” errors and garbled strings, sometimes containing
the actual string, and other times containing junk (like Unicode chars).
Again, given what I have laid out in this article about my code architecture, functions, and data models, can you spot the bug? Seriosuly, I encourage you to take a minute before reading further to think about what the bug is…
/*
██████ █████ █████████ █████ █████ ███ ███
░░██████ ░░███ ███░░░░░███░░███ ░░███ ░░░ ░███
░███░███ ░███ ██████ ███ ░░░ ░███████ ██████ ██████ ███████ ████ ████████ ███████░███
░███░░███░███ ███░░███ ░███ ░███░░███ ███░░███ ░░░░░███ ░░░███░ ░░███ ░░███░░███ ███░░███░███
░███ ░░██████ ░███ ░███ ░███ ░███ ░███ ░███████ ███████ ░███ ░███ ░███ ░███ ░███ ░███░███
░███ ░░█████ ░███ ░███ ░░███ ███ ░███ ░███ ░███░░░ ███░░███ ░███ ███ ░███ ░███ ░███ ░███ ░███░░░
█████ ░░█████░░██████ ░░█████████ ████ █████░░██████ ░░████████ ░░█████ █████ ████ █████░░███████ ███
░░░░░ ░░░░░ ░░░░░░ ░░░░░░░░░ ░░░░ ░░░░░ ░░░░░░ ░░░░░░░░ ░░░░░ ░░░░░ ░░░░ ░░░░░ ░░░░░███░░░
███ ░███
░░██████
░░░░░░
*/
va_array_append(_n) may call realloc at any point, and thus invalidate all pointers
previously stored anywhere, including the context va_arrays.
AGHHHHH!!!
This was such a stupid bug, and stupid oversight on my part, and the worst part is the solution is so simple; I’ll leave a link for an article called Handles are the better pointers3 for the reader’s curiosity, it’s a good article, and embarasingly something I had read a while before embarking on this project, so I already knew the correct approach. Anyway, after realising this, I refactored all my parsing code to use handles instead of pointer4.
The fixed code, for string expression handling at least, looks like this:
// parser.h
typedef struct string_expression
{
String_Handle handle;
size_t len;
} String_Expression;
// parser.c
Tyger_Error parse_string_expression(Parser *p, Parser_Context *ctx, Expression *expr)
{
Tyger_Error err = {0};
size_t str_value_handle = va_array_next_handle(ctx->strings);
va_array_append_n(ctx->strings, p->cur_token.literal.str, p->cur_token.literal.len);
va_array_append_n(ctx->strings, PARSER_NULL_TERMINATOR, 1);
const char *str_value = va_array_address_of(ctx->strings, str_value_handle)
*expr = (Expression) {
.kind = EXPR_STRING,
.expression.string_expression = (String_Expression) {
.value = str_value,
.len = p->cur_token.literal.len
}
};
return err;
}
Where String_Handle is just an aliased size_t for an index in the array, and
va_array_next_handle just returns the current length of the dynamic array, as that’s
just where the next element will be inserted (i.e. the next free space).
I should also note that even though I only spotted this during string parsing tests, it was obvious, once I figured out that my issues were down to pointer invalidation, that this affected every single parsing function which interacted with those dynamic arrays4. Interestingly it’s a good thing that this showed up because of me being lazy and wanting to run some integration tests on the simplest data type I was tracking (strings). Why? Well imaging trying to debug this reallocation issue when you have some program comprising 32+ value producing statements, I don’t think I would have found it as quickly as I did by just watching my strings since only “a single object” - in reality 32+ objects because each char is considered an object for purposes of my functions - and that is easy to trace in a debugger because it’s the result of stepping over 1 line of code. This is also probably a demo as to why just stress testing/fuzzing systems and throwing junk at them to see what happens is a good idea, again I just threw some random strings which were crafted for force reallocation. Granted, this could have been avoided had I written some tests elsewhere, so that’s a lesson learned for next time.
I think this bug alone has helped solidify a certain mental model for memory allocation, and ensuring you think about the flow of data through your application’s lifetime, exactly the thing I wanted to get out of doing a “real”, and more complicated project - you don’t really see stuff when you just look over the simple examples that you see littering the internet for C programming tutorials/explainers. Also better to spend a few hours banging your head against a wall on a “toy” project when you encounter these issues, so you know how not to encounter them again when you work on production code.
// An example of the overly simplistic examples of memory mamngement you see littering
// the internet in reference to C/C++
char *foo() {
char *buffer = malloc(100);
return buffer;
}
void bar() {
char *buffer = foo();
// ... do something with buffer ...
free(buffer);
}
Error Handling
Error handling is a bit of a pain in C (and C++, but if you’re a fan of exceptions
you have those at least), and I wanted to do something a little better than just
returning either NULL pointers, or integer error codes. Now whilst in practice what
I have initially scaffolded is just an error code, I do aim to extend this after
I get program evaluation functioning, but what I do in my parser is return structs
which represent the error, Tyger_Error:
typedef struct tyger_error
{
Tyger_Error_Kind kind;
} Tyger_Error;
The kinds of errors tracked in the language, at this level, include syntax errors
(e.g. declaring a variable with no ident: var = 10;), and integer parsing errors
(returned when a call to atoll returns 0, and the parsed string was not "0").
The main downside of choosing to handle errors like this, rather than return pointers
to parsed expressions/statements, is that I now get into more complex data flows
(as previously laid out) due to the need to pass round multiple
out/inout params, i.e. parameters to which a result is written, and parameters
which both provide data and where the result is written to, respectively.
If I were just returning pointers, which may be null in case of an error, then
all my functions simply would accept the parser state, and just return the null pointer
and check this. Again, for reasons laid out earlier, namely I wanted to simplify
the memory management of my data, I chose to trade off a more complex data flow for
improving the mental load required for wide scale memory management. This approach
also does allow for expansion later into a better error reporting system without later,
more major refactors, for example:
typedef struct tyger_error
{
const char *what; // A formatted error message, as a heap allocated string
Location where; // A struct showing where the error was found, containing line and col
Tyger_Error_kind kind; // A simple marker of what class of error this was
} Tyger_Error;
Misc Issues From Development
This is mainly a round up of a few things which don’t really fit anywhere, but were big enough headaches or just weird minor issues that I think need to be noted here, if for no other reason so somebody else doesn’t tear his hair out trying to figure it out.
Forgetting How println Was Defined
When I initially tried to parse call expressions, how function calls are defined,
I forgot that TK_PRINTLN was how the println keyword was lexed, i.e. as its
own keyword, not an ident, which would actually be more sensible as I even noted
in code5. This something I will be changing later, particularly once I have a
working eval loop going; it will also require me to probably work a peek_token_is
into the relevant case for parsing idents to check for this.
Forgetting The Existence of Commas
As alluded to earlier, the parser just wasn’t aware commas were a valid token, as
the lexer didn’t support them6. This was a headache when parsing functions, namely
println as this is the only supported function, as I couldn’t figure out why multi-arg
parsing was just failing for some syntax error reason. This is something that was
missed from initial lexer test cases and will need to be added later to check things
(which will require a minor addition to the code gen script).
Cross-Compiler Compatibility
Most of my development is done on Windows, although in future this will change
as I plan to move back to Linux (for the most part) thanks to Microsoft’s efforts
to ruin Windows. Now, I do run my tests in CI, which uses GCC on Linux, but I because
I don’t usually run these locally (I do have act running on WSL, but I don’t always
run them) so it can take a while for it to become obvious that these are problems.
Warning Levels
In my experience, attempting to use /Wall warning levels with MSVC is just a pain,
and nothing will ever compile because it complains about things in the standard
library. This however does lead to problems, as you compile on /W4 level, and since
this doesn’t catch certain problems, you only learn in CI that these are issues.
One example of this is the snprintf function, which is used by my string builders
for debug tracing7. Initially, the wrapping functions which append strings all
call this internally, I did however encounter a fun compiler discrepancy between
MSVC and GCC, namely that with my Windows config this code does not error:
void string_builder_append(String_Builder *sb, const char *str)
{
// ...
int bytes_written = snprintf(&(sb->buffer[sb->len]), bytes_to_write + 1, str);
// ...
}
The problem here is that you can’t just use snprintf to append a c string to another
buffer, the fix for this was simple, it was simply to change the call to be
snprintf(&(sb->buffer[sb->len]), bytes_to_write + 1, "%s", str);. But this is one
of the weird differences in compilers and platform development you encounter; I’m
not saying this is exclusively a GCC/Clang problem, what I am saying is that were
development with /Wall not miserable on Windows, I would probably have seen this.
A Small Rant About Comments
I swear I find the dumbest bugs in everything - over the last few months for example, I can semi-reliably cause a rendering bug in Slack where, if I drag the window from one monitor to another quickly and have it resize in quick succession, it just renders the chat content at like 3/4 height. But anyway, my hate for chat clients will come another day, I’m here to vent my hatred for compilers!
Who would like to guess the problem with this test case code? Hint, it’s specifically a problem with GCC/Clang, and think about macro rules.
TEST(ParserTestSuite, Test_Operator_Precidence)
{
struct Precidence_Test
{
const char *input;
const char *ast;
};
std::vector<Precidence_Test> test_cases{
// ...
{ "1 + 2 - 3 * 4 / 5;", "(- (+ 1 2) (/ (* 3 4) 5))" },
// (-)
// / \
// (+) \
// / \ \
// (1) (2) (/)
// / \
// (*) (5)
// / \
// (3) (4)
// ...
};
};
Well here’s (a recreation of) the compiler error message (from godbolt):
<source>:7:54: error: multi-line comment [-Werror=comment]
7 | // / \
That’s right, the backslashes in my ASCII art representation of the parse trees of infix expressions escape the proceeding line’s backslash denoting a new comment! Yes I’m serious, yes there is a commit for this8, yes I did yell into cyberspace fixing it, and for posterity I will just paste the commit message here as I think it summarises this best:
fix -Werror-comment compiler error on GCC/Clang
Apparently GCC/Clang don't like handling the \ char in comments
and assume that this means you want to escape the new line and
join this line with the next. Because this is ObViOuSlY sEnSiBlE
bEhAvIoUr DuMmY ¯\_(ツ)_/¯
I have many other words I could say about this, but I will just choose not, I will
simply say I am so glad that programming generally does not come up against this
utter nonsense often because I would have quit. The fix was simple, just use /* */
multi-line comments, hardly a Sisyphean task, but this is just stuff you shouldn’t
have to get involved with or waste neurons on! Maybe there’s good reason for this,
I don’t know, hopefully this saves someone 5 minutes.
Closing Remarks
Parsing has been done! This now lays the foundations for later evaluation, i.e. the thing which I think any language designer wants to get to; it is to be seen whether my architecture here is any good for implementing evaluation. I also think that doing this project and having to explain certain things - like the memory manipulation flow for parsing expressions, and Pratt Parsing - has helped me better understand some of these rather abstract concepts. I’ll leave a few extra resources here I used to help understand Pratt Parsing, and of course, buy book!
I will also close with this, I think writing is proving the point of “don’t make the perfect the enemy of the good”, a misquote, but the sentiment of don’t make inability to achieve “perfection” [in the moment] a reason not to make something which is “just” good. I could have finished this article, and the first pass of this project a few months sooner had I just started trying to paper a bad explanation of both Pratt Parsing, and the flow of memory through my expression parsing; I’m not even convinced that my explanation now is phenomenal, however I am actually happy with it, even with several rewrites in the background.
Additional Resources
There are other books in the world that cover this topic (parsing, and language development more generally), and one which is on my reading, I will list a few here:
- Compilers: Principles, Techniques, and Tools
- I have not read this one, but am aware that it’s a well cited book for compiler developers, and is on my reading list
- Crafting Interpreters
- this is freely available, and does feature the “from scratch” approach to development
- Build Your Own Lisp
- this is a different kind of book, also freely available
- from my reading of it, there’s a bit too much “use this, and it’ll work” for my liking, but maybe this is more your thing
I may have to do a review of these all one day, comparing them to the Interpreter Book, and go over what they seem to do well as learning resources.
There are also a few videos I’ll link, which cover some practical aspects of compiler development, parsing, and operator precedence, from somebody developing a C++ replacement (Jonathan Blow, creator of JAI):
- Discussion: Making Programming Language Parsers, etc (Q&A is in separate video).
- Discussion with Casey Muratori about how easy precedence is…
Finally, a couple of links on Pratt Parsing which were of varying usefulness, and are collated here for completeness:
- https://tdop.github.io/
- https://crockford.com/javascript/tdop/tdop.html
- https://journal.stuffwithstuff.com/2011/03/19/pratt-parsers-expression-parsing-made-easy/
- https://dawoodjee.com/blog/pratt-parsing/
- https://matklad.github.io/2020/04/13/simple-but-powerful-pratt-parsing.html
- https://dl.acm.org/doi/abs/10.1145/512927.512931